
Very little these days escapes the reach of machine learning (ML) and, more broadly, artificial intelligence (AI). Antibodies have caught the AI train, as over the past several years, major biopharma companies have jumped on board, hoisting up companies that pioneer ML approaches for therapeutic development.
Undoubtedly, such approaches could revolutionize antibody discovery, and researchers have already made impressive progress. However, for AI to successfully develop truly novel antibodies, its models need access to broader datasets and more high-throughput experimental validation.
Now, a team from the Institute for Protein Innovation (IPI) and Harvard Medical School (HMS), led by senior scientist Deepash Kothiwal, reports a novel framework for making synthetic recombinant antibodies that can generate data specifically optimized for ML integration. Not only did the platform accelerate and streamline antibody development, but the application of ML tools also unearthed novel protein binders that would have been missed using traditional laboratory methods alone.
“It’s all about integration,” says Rob Meijers, lead author and head of neuroscience at IPI. “There are excellent machine learning efforts and high-caliber scientists running them. But for the models to work, you have to combine them with the right training data.”
Making a library and making it diverse
Obtaining that data isn’t easy. Historically, researchers have relied on animal immunization to generate what are known as polyclonal and monoclonal antibodies. Problems with reproducibility, renewability and cross-reactivity later prompted scientists to develop non-animal technologies, including phage and yeast display.
To perform phage or yeast display, one begins by building a library of structurally diverse antibody genes. This library recreates the potentiality of an embryonic immune system, with wide versatility due to a mix-and-match scheme combining two types of amino acid chains (heavy and light) that carry snippets of highly variable sequences.
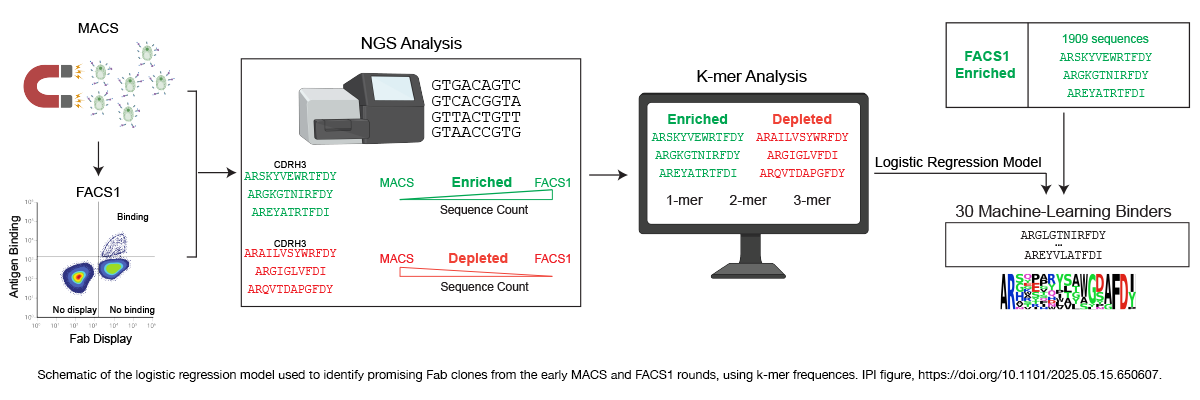
The genes encode a vast repertoire of antibody fragments (Fabs), which the phage or yeast display on their surfaces. Upon addition of an antigen target, a pool of Fab-bearing yeast will bind to varying degrees. A good selection strategy and a process of elimination funnel the pool down to a set of strong binders, which scientists engineer recombinantly into synthetic antibodies.
One limitation of published libraries is their validation using only a limited pool of targets, typically the receptor-binding domain (RBD) of the spike protein of SARS-CoV-2 or interleukins, says Kothiwal.
“We wanted to make a library that targeted a diverse set of antigens, high-profile therapeutic targets, or those interesting in neuroscience,” he says. “We wanted to challenge our library and see if we could win.”
Winning also meant overcoming other hurdles. Antibody repertoires are vast and diverse, carrying hundreds of amino acid sequences, each needing to bind a specific target. Thus, dealing with all the sequence data to sift through what makes a good versus a poor binder becomes a daunting challenge for basic computational modeling.
The IPI team found a way around the hurdle by homing in on one tiny loop of a three-looped region on the antibody’s heavy chain. Called the complementarity determining region 3 (CDR3), this amino acid bit is the part of the antibody that makes unique contacts with its target, a so-called “paratope” holding the most essential information necessary for antigen recognition.
The team used a combinatorial gene synthesis method, devised by Twist Bioscience, to create billions of differing CDR3s. The researchers varied the frequency of amino acids at each position in the 11-17 stretch to mimic a natural human antibody repertoire. Then came tricks to tweak amino acid frequencies and eliminate those patterns that lead to cross-reactivity, aggregation and degradation. Adding in a genetic “barcode,” the IPI team fashioned the CDR3s into “antigen recognition modules” (ARMs), which are amenable to deep sequencing and, most importantly, easily read by machine learning algorithms.
“We made this library to discover binders,” says Nick Hollmer, a senior research associate at IPI and co-author on the paper. “But because of the way it’s designed and the way we’re sequencing, there are massive amounts of data that can be used to fuel machine learning.”
The result was a library of nearly a billion unique yeast clones, each studded with an antibody fragment on its surface, with each fragment containing a different ARM.
“We reduced the complexity, narrowing down a six-dimensional problem to one dimension,” says Meijers. “From that, we could make thousands of antibodies relatively cheaply.”
The 10 contestants
To test the whole schema, the IPI team genetically constructed 10 representative antigens, nine human cell surface receptors and one soluble murine glycoprotein. After running each target through the library and selection protocols, the researchers successfully generated antibodies with robust binding properties for all 10 antigens tested.

The campaign yielded a dataset containing over 60,000 unique CDR3 sequences, and 486 antibodies were tested experimentally and more than 100 of those showed therapeutic-grade biophysical properties. In addition, antibodies were tested as affinity reagents in flow cytometry and immunohistochemistry.
But even more compelling, the antibody campaign generated a dataset that linked the sequence and identity of each ARM with its performance at each stage of the selection process. With new ML technologies proliferating in protein science, the team wondered if this data could be used to predict, early on, whether antibody candidates would make it to the final cut. To find out, the IPI team reached out to Debora Marks and her computational laboratory at HMS.
“IPI has a lot of selection data,” says Aaron Kollasch, formerly a graduate student in Marks’s lab and co-author of the paper. “We thought, ‘Maybe there’s something buried in there, some signal that we can extract.’”
Enter AI
The teams honed in on two closely related targets: ROBO1 and its cousin ROBO2, which share a nearly identical segment at their front N-terminal ends. Of the antibodies obtained during the campaign, some bound to those shared epitopes and, therefore, both targets, while other antibodies would bind at another point, choosing either ROBO1 or ROBO2.
Using the sequence data obtained from ARMs that bound ROBO2’s N-terminal, the Marks team trained a logistic regression model. The researchers then validated the model using similar sequence data independently obtained from the ARMs that became ROBO1 antibodies.
To the researchers’ delight, their ML model successfully distinguished ROBO1 binders that also bound ROBO2N (likely sharing an epitope in the N-terminal region) from those that did not bind ROBO2N (likely binding an epitope outside the N-terminal domain).
Next, the scientists explored whether they could use their model to seek and rescue ROBO2 binders that would have been thrown out at earlier screening stages. Combining deep sequencing data from early selection rounds with ML-based analysis, the team dug up 29 ARMs, which had failed at some screening stage but appeared, via ML, to be strong ROBO2 antibody contenders.

The IPI group then converted those ARMs into full-length antibodies and tested how well they bound ROBO2. The team found that 9 of the top 10, as well as 11 of the ML-derived antibodies, performed as well as—or better than—the ROBO2 antibodies discovered through wet lab screening. Tests for cross-reactivity showed that all 11 ML-derived ROBO2N antibodies also bound ROBO1, consistent with the fact that 94% of the amino acid sequences in their N-terminal domains are identical. Finally, no antibodies bound to non-ROBO antigens that were used as negative controls.
A similar approach was then applied to another antigen, PD-L2, for which two antibodies had been experimentally obtained, successfully mining another 19 antibodies. “It turned out that there were some hidden gems,” says Kollasch, now an AI protein engineer at Base Camp Research.
Indeed, it was a significant boost facilitated by the machine learning protocol.
“We’ve shown that deep sequencing of early selection rounds, combined with ML-based analysis, can predict high-quality antibody candidates,” says Meijers. “This approach highlights the power of a minimal library approach. By limiting the complexity of the antibody sequence data, it is much easier to access the untapped potential of early-round sequence data and catalyze the use of machine learning in antibody discovery workflows.”
Given this success, the IPI team has decided to release the datasets derived from these discovery campaigns for other computational biology teams developing machine learning models. These might advance in silico methods meant to enhance antibody development through techniques like epitope binning, affinity maturation and zero-shot antibody discovery.
“The amount of data we have on antibody-antigen complexes is fairly limited,” says Kollasch. “So, any of the models where you learn from that data will be limited. As the IPIs data set grows, I think that a model fit to the IPI sorts would be something people would have a lot of interest in.”
Special thanks to the IPI team, including: Deepash Kothiwal, Nick Hollmer, Anita Ghosh, Roushu Zhang, Murali Anuganti, Mina Abdollahi, Zachary Anderson, Filmawit Belay, Matthew Salotto, Sophia Ulmer, Youssef Atef AbdelAlim, Satyendra Kumar, Mahesh Vangala, Chang Yang, Joseph Jardine, André Teixeira, Deborah Moshinsky, Haisun Zhu, Shaotong Zhu and Rob Meijers.
Sources:
Rob Meijers, rob.meijers@proteininnovation.org
Aaron Kollasch, LinkedIn
Writer:
Trisha Gura, trisha.gura@proteininnovation.org
About IPI
The Institute for Protein Innovation is pioneering a new approach to scientific discovery and collaboration. As a nonprofit research institute, we provide the biomedical research community with synthetic antibodies and deep protein expertise, empowering scientists to explore fundamental biological processes and pinpoint new targets for therapeutic development. Our mission is to advance protein science to accelerate research and improve human health. For more information, visit proteininnovation.org or follow us on social media, @ipiproteins.